Dimensional Modeling With DBT
2024. 9. 29. 21:18ㆍ카테고리 없음
등장 배경
- 전통적인 DBMS 모델링에서 겪었던 문제
- 테이블에 중복 없이 데이터를 저장하기 위해 여러 테이블로 나누는 정규화 과정을 거치게 되며, 복잡한 조인 작업을 필요로 함.
- 테이블 간의 조인이 자주 발생하면 성능 저하 및 비용 증가를 유발할 수 있음.
- DBMS와 다른 OLAP DataWarehouse에서 다른 설계가 필요함.
- DBMS에서는 라이브로 다수의 유저가 변경 작업이 있음, 이에 따라 중복을 피하고 일관성을 유지하는 것이 중요함.
- Data Warehouse에서는 분석 성능을 높이기 위해 데이터 중복을 허용하고, 비정규화된 테이블 구조를 채택하는 경우가 많습니다. 이러한 방식은 데이터 조회를 빠르게 하고, 복잡한 조인 없이 데이터를 효율적으로 분석할 수 있음.
- 따라서 OLTP와 다르게 데이터를 효율적으로 분석하고 insight를 뽑아낼 수 있는 모델링 방법이 필요함.
- 요약
- 현대의 Data Warehouse에서는 DBMS와는 다른 분석 목적에 맞춘 모델링 방식이 요구되며, 이를 위해 Dimensional Modeling이 도입되었음.
Dimensional Modeling
OLAP의 특성을 갖는 Datawarehouse에 Dimensional Modeling을 이용해 효율적으로 데이터 쿼리 및 분석하기 위해 설계된 모델링 방법이다.
Fact Table
- 물리적 활동으로 발생한 이벤트를 저장하는 테이블.
- Dimensional Table과 연결하기 위한 Foreign Key가 함께 있어야함.
- Null이 되면 안됨.
- e.g)
- Transaction Fact Tables: 개별 이벤트를 기록하는 테이블임.
- 은행에서 입금
- 카드 결제
- 비행기 발권 등등
- Periodic Snapshot Fact Tables: 일정 기간 동안의 상태를 기록.
- 한 주에 한번, 한달에 한번 씩 특정 테이블의 상태를 기록한 테이블
- 하루에 한번 동의 내역을 기록함.
- Factless Fact Tables: 측정값 없이 이벤트를 기록.
- 마케팅에 참여한 회원인지(True/False) 기록
- 출근한 직장인지 확인
- Aggregated Fact Tables: 세부 데이터를 요약해 분석등에 사용할 수 있고 성능이 좋은 테이블.
- 월별 편의점 결제 데이터
- 연령별, 성별 결제 데이터
- Transaction Fact Tables: 개별 이벤트를 기록하는 테이블임.
Dimension Table
- Fact 테이블의 값을 설명하기 위한 값들이 저장됨.
- Fact 테이블과 연결될 수 있는 키를 꼭 구비해야함.
- 비정규화 된 상태로 테이블이 구성되어야 함.
- 키와 많은 양의 메타 데이터가 붙어 있을 수 있음.
- Fact와 연결될 때 적은 Join연산을 만들어 낼 수 있음.
- 중복된 값이 row 별로 보일 수 있음.Product_ID Product_Name Category Brand
1 T-Shirt Apparel Nike 2 Running Shoes Footwear Adidas 3 T-Shirt Apparel Nike - e.g)
- 유저 생일, 나이, 주소, 성별
- 특정 매장의 위도, 경도, 도시
Star Schema
- 1990년 KimBall 박사님이 제안한 Dimensional Modeling 방법론.
- 중간에 Fact Table을 두고 Foreign Key를 이용해 다른 Dimension Table에 연결해서 사용함.
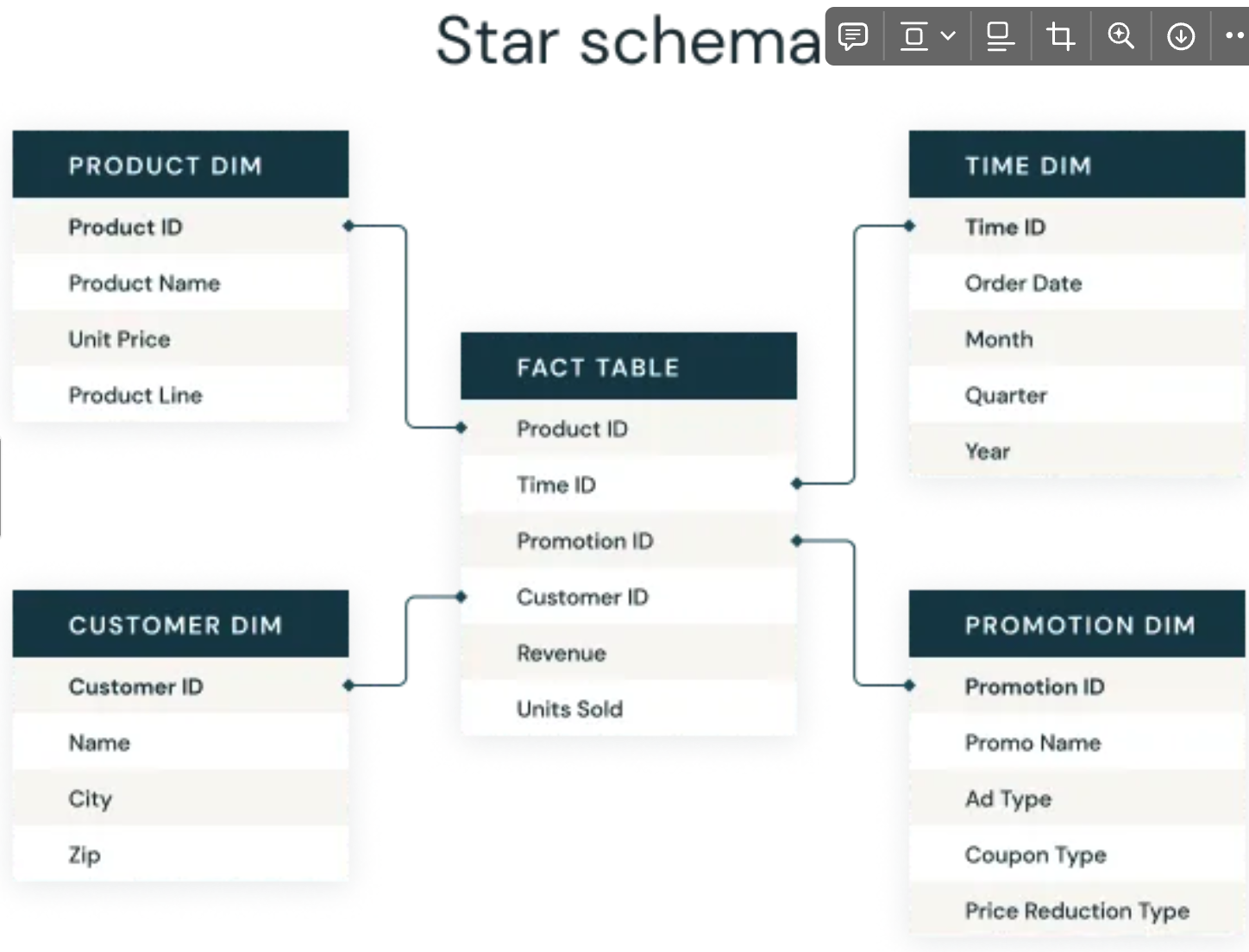
- DBMS에 정규화된 모델에 비해서 Fact와 Dimension의 Join이 걸려 적은 연산이 발생하고 빠르다.
- Dimension Table의 경우 비정규화이며 중복된 데이터가 발생한다.
Grain
- 테이블의 행이 어떤 것을 의미하는지 가장 작은 단위를 결정하는 기준.
- 데이터 해상도를 세밀하게 진행해서 사용자의 요구에 따라 자유성이 있게 표현할 수 있음.
- ex) 이벤트 한건 한건 표현 가능
- 반면 Aggregated하게 Grain을 설정해서 성능 및 분석에 있어서 유리함.
- ex) 이벤트를 Aggregate 함수들을 이용해 테이블을 만듬.
- 명확하게 정의되지 않으면 추후에 분석 및 이용에 있어서 혼란이 올 수 있음.
- e.g)
- 카드 결제 데이터: 특정 매장에서 특정 유저가 특정 날짜에 구매한 아이템.
- 웹사이트 방문 로그: 특정 사용자가 특정 시간에 특정 웹페이지를 방문함.
SCD(Slowly Changing Dimension)
시간이 지남에 따라서 Dimension Table의 값이 변경되게 되는 이를 어떻게 관리할지 타입이 정리되어 있음.
- Type 0: Retain original
- 변경이 발생해도 데이터를 덮어쓰지 않고 원본 데이터를 그대로 유지한다.
- 불변하는 데이터에 자주 이용함.
- e.g)
- 특정 핸드폰 모델의 시리얼 넘버
- 특정 제품의 출시일
- Type 1: Overwrite
- 기존 데이터를 덮어 씌우는 방식, 변경 전의 데이터를 유지 하지않음.
- e.g)
- 이메일 주소가 변경되면 이전 이메일 주소를 덮어씌움.
- Type 2: Add new row
- 변경되기 전 데이터를 유지한 채 새로운 데이터를 추가함.
- 과거의 데이터를 추적할 필요가 있을 때 사용함.
- 유효기간 관리 및 최근에 변경됐는지 확인할 수 있는 칼럼이 중요함.
- 이력 관리 및 시간의 연속성을 확인하고 싶을 때 많이 사용함.
- e.g)Customer_ID Customer_Name Address Start_Date End_Date Current_Flag
1 John Doe 구미시 상모동 2020-01-01 2023-05-01 N 1 John Doe 구미시 옥계동 2023-05-02 NULL Y
- Type 3: Add new attribute
- 이전과 현재의 데이터를 저장하는 방식
- 직전 상태만 추적이 필요할 때 사용함.
- e.g)User_ID User_NickName Rank_Tier Previous_Rank_Tier
1001 John Doe Gold Silver
- Type 4: Add mini-dimension
- 자주 변경되는 dimension을 따로 테이블을 분리해서 관리하는 type
- 잦은 변경이 있는 경우 사용되며 이 경우 메인테이블의 업데이트 없이 작은 테이블을 업데이트 시켜주면 됨.
- Type 5: Add mini-dimension and Type 1 outrigger
- 1과 4의 방법을 같이 사용함.
- 메인테이블의 타입 4의 테이블의 연결을 위한 key를 갖고 있음.
- 자주 변경되는 칼럼의 경우 4테이블의 변경시에 메인테이블의 해당 키를 덮어씌워 주면 됨.
- Type1 방식으로 지정된 칼럼은 1의 방식으로 덮어씌워 짐.
- e.g)customer_key customer_name address birth_date credit_rating_key
credit_rating_key credit_rating effective_date1 Alice 123 Main St 1985-02-15 100 2 Bob 456 Park Ave 1979-07-23 101 100 A 2023-01-01 101 B 2023-06-01 102 C 2024-01-01
- Type 6: Add Type 1 attributes to Type 2 dimension
- Type2에 Type1 방식을 적용함.
- 일부 속성에서는 과거 데이터를 유지하고 특정 속성은 최신 유저가 필요할 때
- 일부 속성에서 Type 2방식을 적용함, 또 일부 속성에 Type1 적용함.
- e.g) 주소는 이력 추적이 필요하지만, 이름은 최신 정보만 필요할 때Customer_ID Customer_Name Address Start_Date End_Date Current_Flag
1 John Doe 123 Main St 2020-01-01 2023-05-01 N 1 John Smith 456 Oak St 2023-05-02 NULL Y
- Type 7: Dual Type 1 and Type 2 dimensions
- Type1, Type2 둘다 사용하는 방법임.
- 최신 데이터와 이력을 모두 필요할 때 사용함.
- Type1에는 현재의 데이터 Type2는 이력정보를 저장함.
- 2개의 테이블을 만들어서 관리함.
- 테이블1에는 고객의 최신정보
- 테이블2에는 고객의 이력 정보
Dimensional Modeling 설계 과정
- 비지니스 프로세스 정의
- 비즈니스에서 중요한 활동이나 이벤트를 설정합니다.
- Grain 설정
- 위에서 설정한 이벤트를 기반으로 테이블의 row가 어떤 데이터 단위인지 설정
- 단건의 이벤트로 선택할 것인지, Aggregate 된 데이터 요약본일지
- Dimension 생성
- 팩트 테이블의 외래키와 연결해 row에 추가정보를 줄 수 있는 테이블 생성
- 시간, 고객, 제품 지역과 같은 추가정보를 줄 수 있어야 함.
- 키는 고유한 키로 설정하거나 suroggate_key로 만들어야 함.
- Fact 생성
- Grain으로 설정한 물리적으로 발생한 이벤트를 저장하도록 설계합니다.
- 팩트 테이블은 물리적으로 발생한 이벤트와 Dimension 연결을 위한 외래 키가 존재해야함.
DBT에서 적용해보기
- 비즈니스 프로세스 정의
- 이벤트 데이터:
- 카드사 결제 데이터: Hourly & Daily Insert
- 백화점 결제 데이터: Daily Insert
- 대중 교통 데이터: Hourly Insert
- 검색 데이터: Hourly Insert
- 동의 데이터: Daily Insert
- 위 Cron job들이 실행된 후, DBT 모델에서 업데이트 진행.
- 이벤트 데이터:
- Grain 설정
- Grain: 특정 시점에서 한 고객이 특정 매장에서 실행한 개별 결제 거래
- 필요한 컬럼:
- EVENT_TIMESTAMP: 거래 발생 시간
- ABID: 고객 식별자
- 가게 이름 및 우편번호: 결제 가맹점 정보
- 카드 결제 정보
- Fact table 설계
- 포함된 정보:
- 유저 ID: 결제한 고객의 고유 식별자
- 구매처 카테고리: 가맹점의 분류 정보
- 구매 정보: 가격
- 이벤트 발생 시간: 거래가 발생한 시각
- 구매처 이름 및 우편번호: 가맹점의 이름과 우편번호
- 포함된 정보:
- Dimension table 설계
- 유저 개인정보:
- 성별
- 생일
- 개인 고유 키 및 아이디 (이메일, CI, pin 등)
- 개인 거주지 위치
- 가게 정보:
- 가게 주소
- 위도 및 경도 (위치 정보)
- 유저 개인정보:
DBT 활용해서 모델링 해보기
기존 Main 테이블
- One Big Table로 모든 이벤트가 한 테이블에 저장돼 있음.
- 따라서 특정 데이터를 확인하려면 매번 Where 절의 조건이 걸리고
- 유저 정보와 함께 확인하고 싶을 때 JOIN을 해야하는데 큰 연산이 필요했음.
- 최신 유저 정보만 뽑는 쿼리도 또 뽑아야 했음.
- 또 매일 업데이트 되는데 이를 매번 치는 것도 불편했고 변경분에 한해서 업데이트 하는 것도 힘들었음.
Fact 생성
- 카드 이벤트만 가져오게 설정함.
- 필요한 칼럼만 설정해서 간단화 함.
- 카드 결제 이벤트
Dimension 생성
- 유저와 가게에 대한 메타 데이터 정보가 들어있음.
- 가게 정보
- 유저 동의
Fact X Dimension을 합한 테이블 생성
- incremental로 설정되어 있어서 변경분만 업데이트 됨.
- 이렇게 생성된 데이터는 유저 분석 및 BI 툴에서 사용됨.
- 유저와 연결을 위해서는 ABID를 JOIN에 사용함.
- 가게와 연결을 위해서 가게 이름 및 우편 번호를 사용함.
사용처
- BI 툴(Superset)
- Segment 생성
- 구글, 메타 등에 광고를 돌릴 수 있는 유저 모음.
- 특별한 특징이 있는 유저를 타겟하여 Segment를 만들 수 있음.
- 특정 매점 몇 km 이내에 구매력이 있는 유저에 대한 ADID, EMAIL 모음.
- 매달 편의점에 N만원 이상 사용하는 유저 모음.
결론
- OLAP의 Data Warehouse을 효율적으로 사용하기 위해서 모델링한 방법.
- Fact 테이블은 유저가 물리적인 행동이 기록되어 있으며, 연관 된 메타 데이터를 얻기 위한 key가 있어야 함.
- Dimension 테이블은 Fact 테이블을 설명하기 위한 메타 데이터가 있으며, 연결하기 위한 key 필수
- Fact X Dimension을 합쳐서 복잡한 JOIN 없이 빠르게 분석시킬 수 있었음.
- 또 이렇게 생성된 데이터를 기반으로 BI 및 Segment 등을 생성하는데 사용할 수 있음.
- 또 DBT와 함께하면서 복잡한 쿼리 간소화, ETL 과정 자동화, 자동화 된 스케쥴링 등의 장점을 얻을 수 있었음.
DBT와 관련된 코드는 회사 내부 보안 이슈로 공유하지 않습니다. 궁금한 점 있으시면 댓글을 달아주세요.