2021. 12. 4. 17:27ㆍ공부일기
DynamoDB 데이터 다른 테이블로 마이그레이션 하기
회사에서 일한지 어언 2개월이 지났다. 하나의 api를 테스트 중 한가지 이상한 점을 발견했다. DynamoDB 테이블 설계가 잘못된 것이었다. 우선 ID를 메인키로 데이터를 구분해주었는데 ID를 포함해 하나의 칼럼에 따라서 데이터가 구분이 되어야 하는데 (현재 상황에서는 당연스럽지만)ID가 같다면 데이터가 덮어씌어져서 초기 설계부터 잘못되어 있었다.
그래서 해결책은 ID와 하나의 칼럼을 복합키로 만들어서 데이터를 구분할 수 있게 해주어야 했다. 하지만 기존에 만들어진 테이블을 수정할 수 는 없었고 하나의 데이터도 잃지 않고 칼럼은 다 같으니깐 sort key를 추가해서 테이블을 만들어 옮기는 것이 중요했다.
Dynamodb에서 자체적으로 제공해주는 back up기능은 테이블의설정을 변경하지 못한채 데이터를 추가하는 방식이라 지금의 문제를 해결하지 못했다. 해결을 원하는 조건은 아래와 같다.
- 테이블의 설정을 변경할 수 있어야한다.
- 데이터를 하나도 잃지 않고 옮겨야 했다.
- 기존 api와 문제가 있게 작동되면 안된다.
따라서 나는 많은 aws 중에서 처음보는 Data Pipeline을 사용했다. 검색하면 아래와 같이 보인다.

나는 위와 같은 문제에 대한 해결책을 공유할거라 data pipeline이 무엇인지는 설명하지는 않겠다.
우선 진행 순서는 이렇다.
1. 옮기고 싶은 테이블의 데이터를 먼저 백업(데이터 파이프라인 이용)
현재 dynamodb에서 제공하는 가장 기본의 s3로의 백업은 안된다 xxxxx 3번 과정인 복구가 안된다.
2. 설정을 변경한 새로운 테이블을 만듬.
3. 새로 만든 테이블에 백업한 데이터를 옮김 (데이터 파이프라인 이용)
안타깝게고 아래의 사진과 같이 아직까진 한국을 지원하지 않는다. 그래서 테스트는 가장 가까운 도쿄로 진행했다.

도쿄로 들어가면 바로 기타 등등의 설명과 시작하라는 버튼이 보인다.

Get Started Now를 눌러보면 여러 설정화면이 보인다. 그 중에서 Source를

위의 설정을 눌러주면 아래와 같이 파라미터를 설정할 수 있는 옵션들이 나온다.

여기서
- 백업할 데이터를 담아놓은 테이블
- 백업한 데이터를 저장할 s3 폴더
- 그리고 DynamoDB를 이용할 Region, s3, ec2 등등 모두 여기서 작성한 Region에서 실행된다.
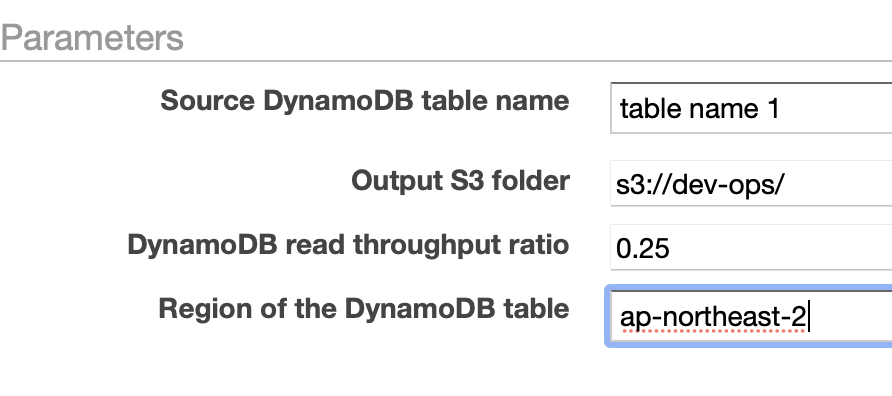
여기서 작성한 데이터들은 다 더미 데이터이다. 그리고 한국에서 실행하기 위해서는 ap-northeast-2를 이용해주면된다.
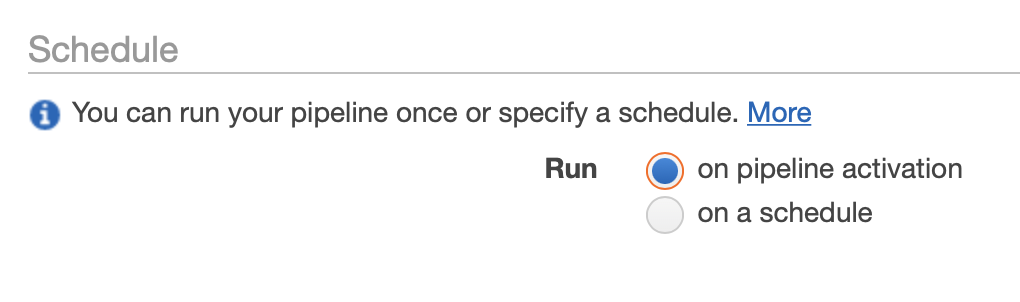
설정 후 바로 실행하고 싶다면 on pipline activation을 설정해준다.
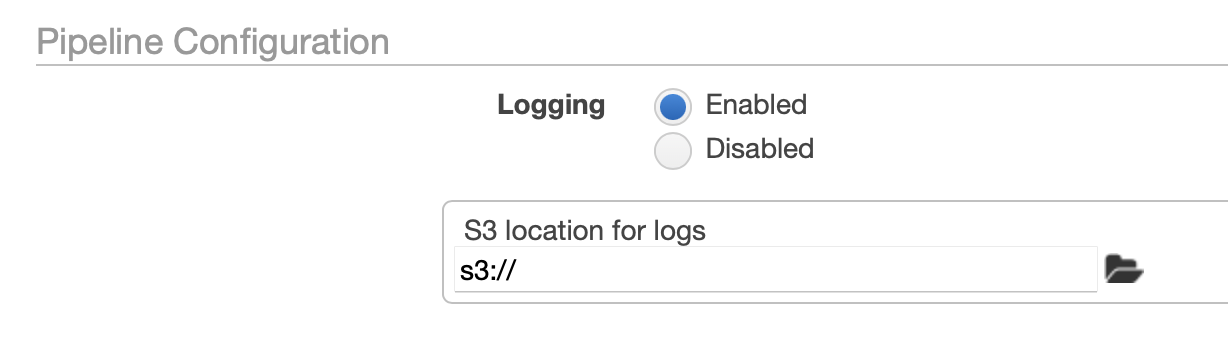
실행되며 나오는 로그도 s3 어디에 저장할지 정할 수 있다.

또 role 등을 설정해주어야 한다. (s3, dynamodb 등에 접근할 수 있는 권한을 주는 것 같다.)
그리고 여기서 중요한 점이 있는데 여기 본적인 ec2 instance type이 매우 옛날 버전으로 되어 있다. 미국은 상관없으나 한국에 있었으면 지원되지 않는 ec2 버전이라 에러가 발생하더라 ㄹㅇㅋㅋ 이것 때문에 에러가 엄청 많이 발생했다. 너무 고생했다....
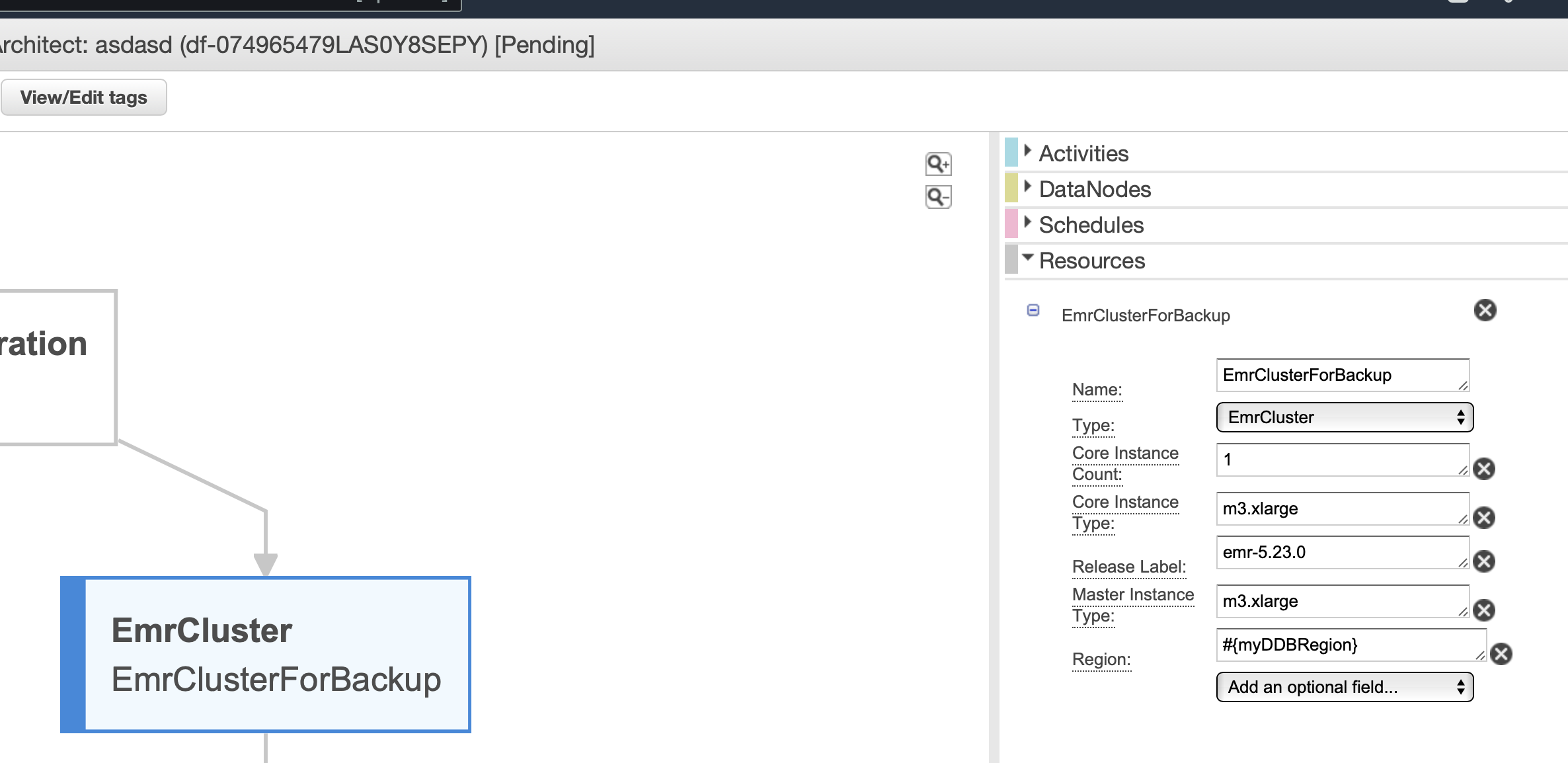
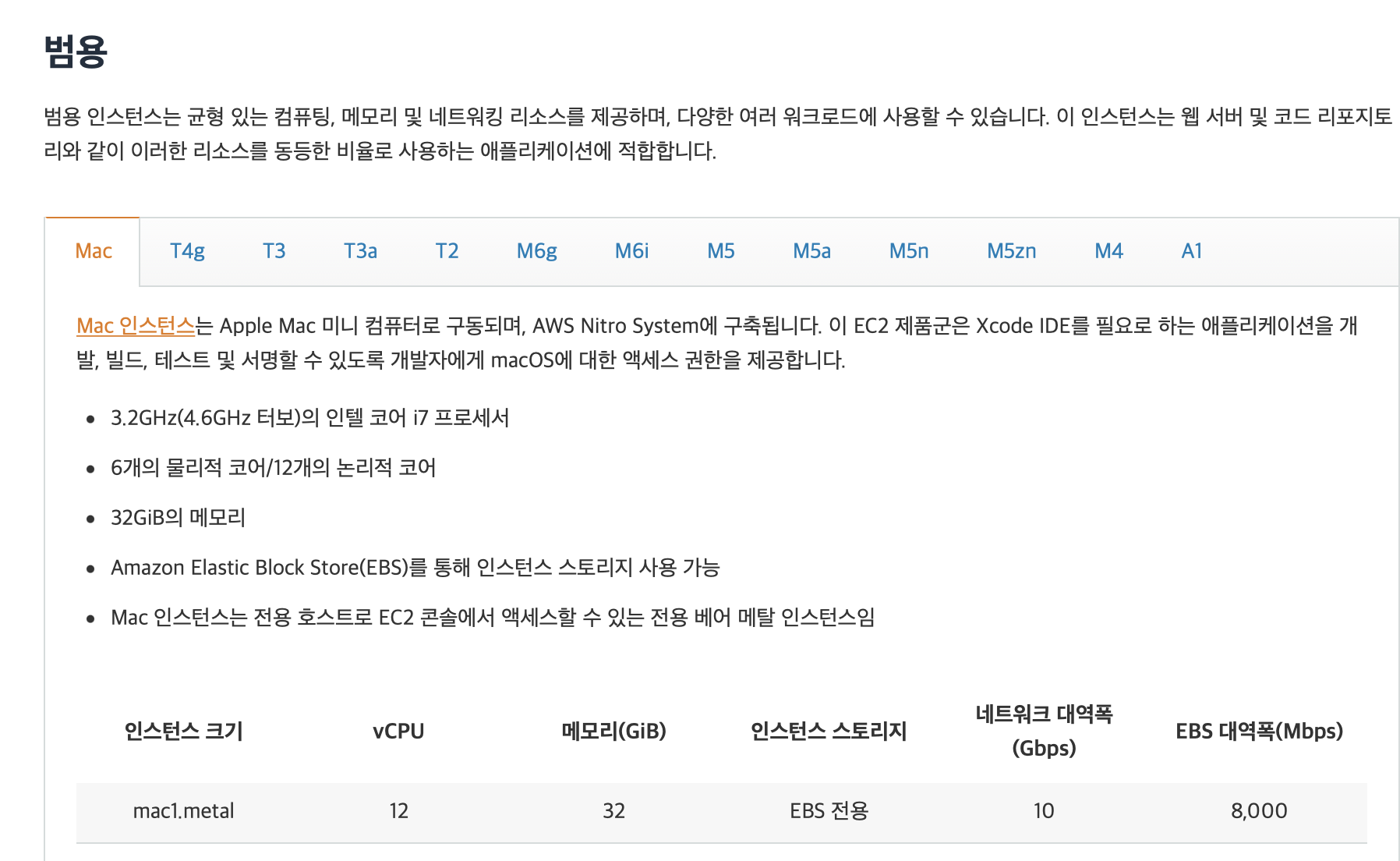
여기 EmrCluster 박스를 눌러보면 m3.xlarge로 설정되어있다. 아래 사진을 보면 M3는 존재하지 않는다... ㅋㅋㅋㅋ
그래서 나는 M5.xlarge로 만들어서 백업을 시작했다. 데이터가 적은 것은 엄청 빠르게 실행되었지만 많은 것은 오래 걸려서 빠르게 진행하고 싶다면 좋은 인스턴스를 골라서 실행하면 된다.
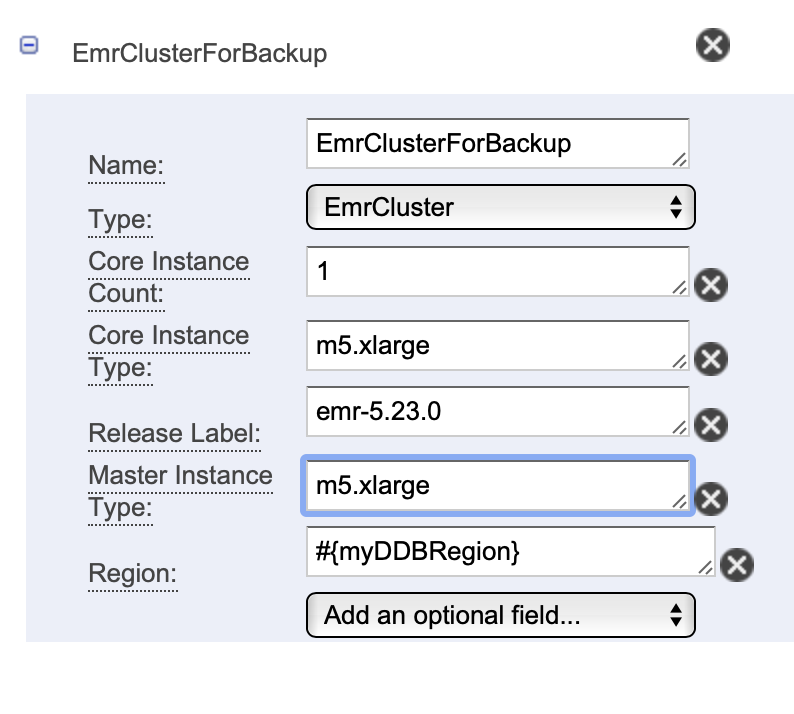
위와 같이 m5.xlarge로 바꿔준 후 위의 save 버튼을 눌러준 후 Activate를 눌러주면 바로 실행된다. 그리고 Running이 진행되다가 Finished가 뜨면 종료된다.
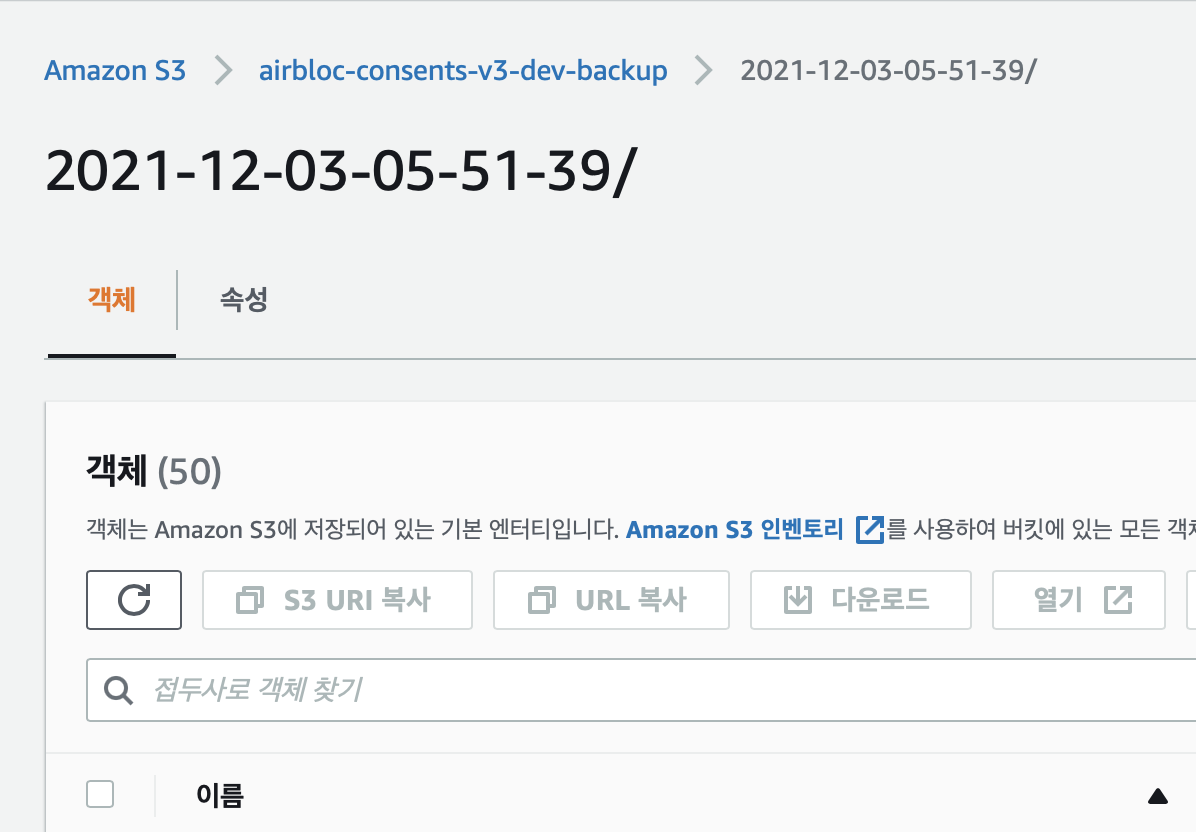
저장을 기록한 s3에 백업을 진행한 날짜의 이름으로 데이터가 저장되어있다.
'공부일기' 카테고리의 다른 글
| TFBO(Test, Fix, Benchmark, Optimize) (0) | 2023.12.11 |
|---|---|
| DynamoDB 데이터 다른 테이블로 마이그레이션 하기(AWS Data Pipeline) - 2 복구하기 (0) | 2021.12.04 |
| 09/29 AWS 공부(ECR, Kinesis firehose, S3 buckets) (0) | 2021.09.29 |
| Git Ops (0) | 2021.09.24 |
| Terraform tutorial - 2. Build Infrastructure (0) | 2021.09.24 |