2024. 6. 24. 16:06ㆍgolang
Golang PGO(Profile-guided optimization)
목차
- PGO란?
- PGO의 원리
- Golang에서 PGO의 구현
- Golang에서 사용하기
- FAQ
- 결론
- 참고 자료
PGO란?
Golang 1.20에서 테스트 배포 후 유저의 피드백을 받아서 1.21 버전(2023년 9월 5일)에서 Production에 배포됐습니다. (링크) Golang에서 이전과 다르게 병목된 부분을 분석하기 위해서 프로파일링을 하는 것이 아닌 컴파일 단계에서도 어플리케이션을 최적화하기 위해서 도입됐습니다.
컴파일러 입장에서 컴파일 과정에서 프로그램을 실행해볼 수 없기 때문에 어떤 부분의 코드가 자주 실행되고 병목현상이 발생하는지 알 수 없습니다. 이 문제를 해결하기 위해 애플리케이션을 Profiling해서 데이터를 수집하고 컴파일 할때 이 정보를 참고해 Guide주어 최적화하는 것이 PGO입니다.
PGO가 적용되고 있는 프로젝트
- Chrome
- browser responsiveness 3~7% faster
- Firefox
- GCC build with PGO is ~10% faster than a vanilla bootstrapped compiler.
- LLVM
- LLVM can decrease overall compile time by 20%
- Microsoft Office
- Visual Studio 일부 시나리오에서 25%의 성능향상이 있었음.
- Unity And Unreal Engine
- 성능 향상은 크게 보지 못했는데 빌드 시간을 크게 단축했다는 글.
PGO 실행 순서
- 실행중인 서비스의 Profiling을 측정해서 아래 데이터를 수집한다.
- Profile Data
- CPU 사용량
- 메모리 사용량
- 함수 호출 수
- 각 부분이 얼마나 자주 실행되는지?
- 어떤 조건 분기가 자주 사용되는지?
- Profile Data
- 수집된 데이터는 다음 빌드에 가이드로 사용함.
- 최적화 코드 식별.
- 최적화 우선순위 정함.
- 예시
- 자주 실행되는 반복문은 최적화를 위해 사용함.
- 실행 빈도가 낮은 코드는 최적화 부분에서 제외 될 수 있음.
- 2에서 분석된 것을 바탕으로 다시 build를 진행합니다.
일반적으로 PGO에서 최적화 하는 부분
- Hot Path 최적화
- 프로파일링을 통해서 수집된 데이터를 분석해서 자주 실행되는 코드 경로를 식별합니다.
- Hot Path로 분류됐을 경우 다음과 같은 최적화 진행
- 메모리 상에서 접근성이 좋은 위치로 이동
- CPU 캐시 등에 위치해서 더욱 빠르게 사용할 수 있게 작용함.
- Code inling
- 함수재배치
- 메모리 상에서 접근성이 좋은 위치로 이동
- Hot Path로 분류됐을 경우 다음과 같은 최적화 진행
- 프로파일링을 통해서 수집된 데이터를 분석해서 자주 실행되는 코드 경로를 식별합니다.
- Branch Prediction Optimization(분기 예측 최적화)
- 조건문의 분기 예측을 통해 최적화를 진행함.
- 프로파일링을 진행하며 분기를 친 기록을 통해서 각 분기에서 어떻게 처리할지 예측을 함.
- 이런 기능이 생긴 배경
- if문을 계산한 후 코드는 모르기 때문에 if문의 계산이 끝나기 전까지 cpu는 놀게됨.
- 따라서 이전의 if를 계산한 기록을 확인해서 if문 예측을 하게 됨.
- 예측을 실패하면 예측했던 연산 결과물을 모두 버리고 복구해야하는 리스크가 있음.
- 현대 cpu에서는 예측률이 90%가 넘어가서 사용함.
- Inline Expansion
- 자주 호출되는 함수를 인라인 확장하여 호출 위치에 직접 코드를 삽입하는 기술.
- 프로파일링된 데이터에서 어떤 함수가 자주 호출됐는지 확인할 수 있음.
- 함수를 호출하는 오버헤드를 제거함.
- 전체 코드가 전반적으로 들어가는 거다 보니 자주 인라인 되는 큰 함수일 때는 많은 양의 코드가 차지하고 있게 되서 메모리를 조금 더 차지할 수 있음.
- Register Allocation Optimization
- 사용빈도가 높은 변수를 CPU 레지스터에 할당해서 메모리 접근시간을 줄입니다.
Golang에서 PGO
1.21에서 부터 사용가능하며 Golang에서 제공하는 profiling 측정한 결과를 피드백으로 PGO 기능을 이용할 수 있게 됐습니다.
Go PGO 구현
PGO를 사용하기 이전의 Golang 컴파일러

IR에서 SSA-IR 사이에 GO Compiler는 Inline, devirtualization, Escape 분석과 같은 최적화를 수행합니다.
SSA-IR 예시
before
int x = 10;
x = x + 1;
x = x * 2;
after
x1 = 10;
x2 = x1 + 1;
x3 = x2 * 2;*IR: 소스코드를 중간표현으로 변경함
*SSA IR: IR을 SSA 형태로 변형함. SSA는 각 변수가 한번만 할당될 수 있도록 코드를 변경함.
*Frontend Passes: 구문 분석(syntax parsing), 의미 분석(semantic analysis), 그리고 초기 중간 코드 생성(initial intermediate code generation)이 포함됩니다.
Devirtualization
- interface 호출을 구체적인 method 호출로 변경함.
- interface로 구현된 추상적인 함수를 호출할때 어떤 함수를 호출할지 run 타임에 실행되는데 찾는 과정을 제거함.
Inlining
- 각 함수에 CanInline을 호출해서 Inline 할 수 있는지 판단합니다.
- HairyVisitor을 이용해서 각 함수의 Inline 비용을 계산합니다.
- 위에서 계산한 비용이 maxInlineBudget(80)을 넘게되면 인라인 할 수 없는 것으로 표시합니다.
- IR 명령어 수가 5K를 넘게되면 maxInlineBudget은 20으로 설정으로 낮춰집니다.
*) HairyVisitor: 중간 코드를 순회하며 함수의 복잡성과 인라인 가능성에 대한 분석을 수행하는 알고리즘
basic-block layout 최적화
- basic block
- 단일 입구, 출구를 갖고 있는 명령어 배열입니다.
- 컴파일러가 프로그램을 분석하고 최적화하는 데 있어 기본단위입니다.
- hotpath의 basic block들이 뭉쳐있는 것이 좋다.
- i-cache의 hit 확률이 더 좋아진다.
- i-cache: cpu의 cache에서 실행할 명령어들을 저장한 cache임
- 조건문에 의해 점프를 하게 되면 기존 가져온 코드 조각들은 필요없어집니다. 자주 실행될 HotPath가 가까이 있다면 CPU가 가져온 명령어가 버려질 확률이 더 낮게 실행될 수 있을 것입니다.
- i-cache의 hit 확률이 더 좋아진다.
ex)
func foo(bool criticalFailure,int iter){
if (criticalFailure){
// cold path
} else{
// hot path
}
}
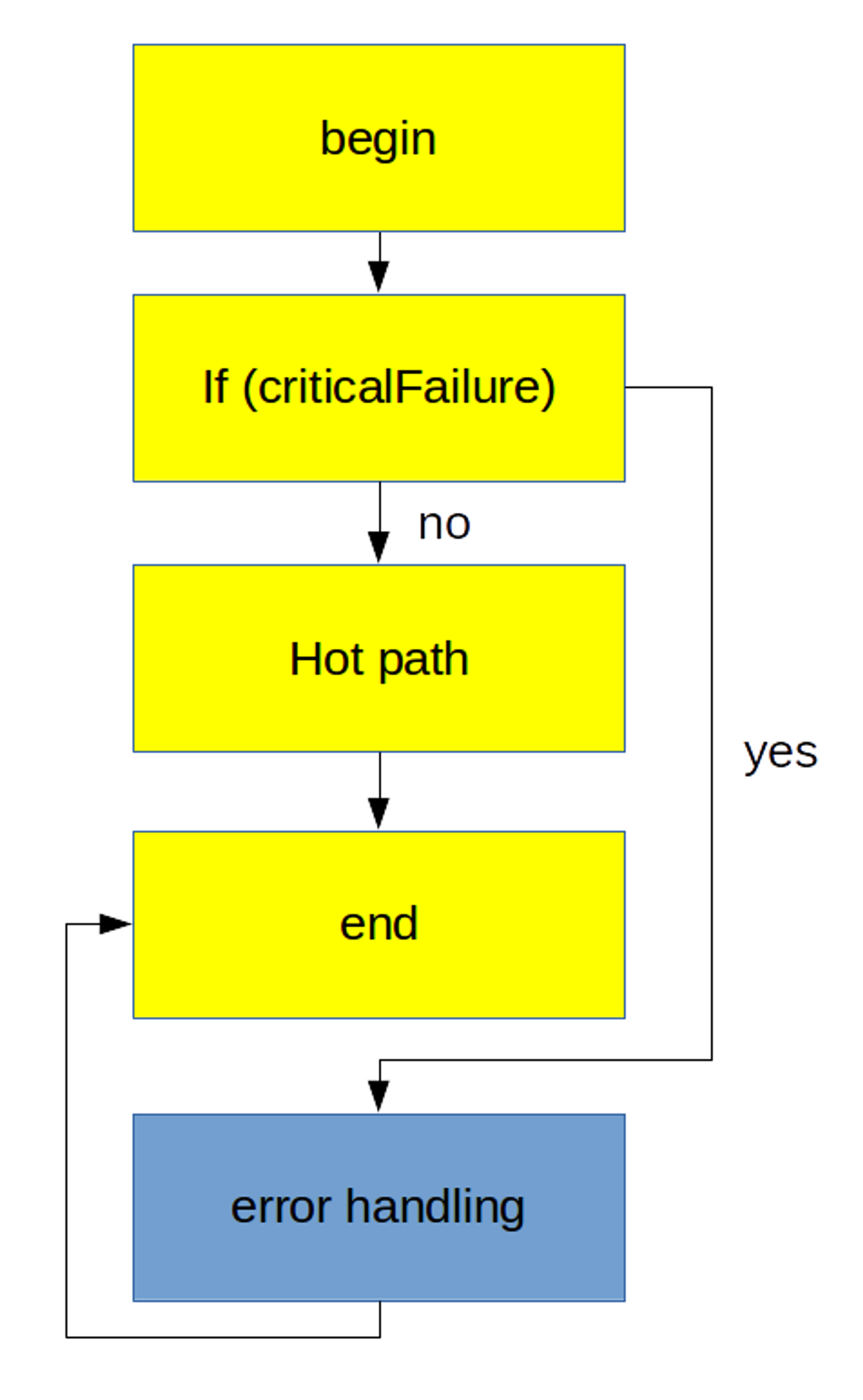
ex) 노란색은 hot path
왼쪽 그림에서 오른쪽과 같이 변경하면 연속적인 hot path 블럭이 존재해 캐시에 존재하는 명령어를 버릴 가능성이 낮아진다.
즉 왼쪽에서는 코드가 실행되면 에러 핸들링 해주는 부분의 코드가 캐시에 존재하게 되지만 Cold Path이기 때문에 상대적으로 자주 사용하지 않고 노란 블럭으로 이동할 확률이 높다. 즉 캐시에 가져왔지만 사용하지 못하고 버려진다. 이런 문제를 해결하기 위해서 Hot Path 블럭을 연속적으로 배치하는 것이 좋다.

PGO를 적용한 Compiler
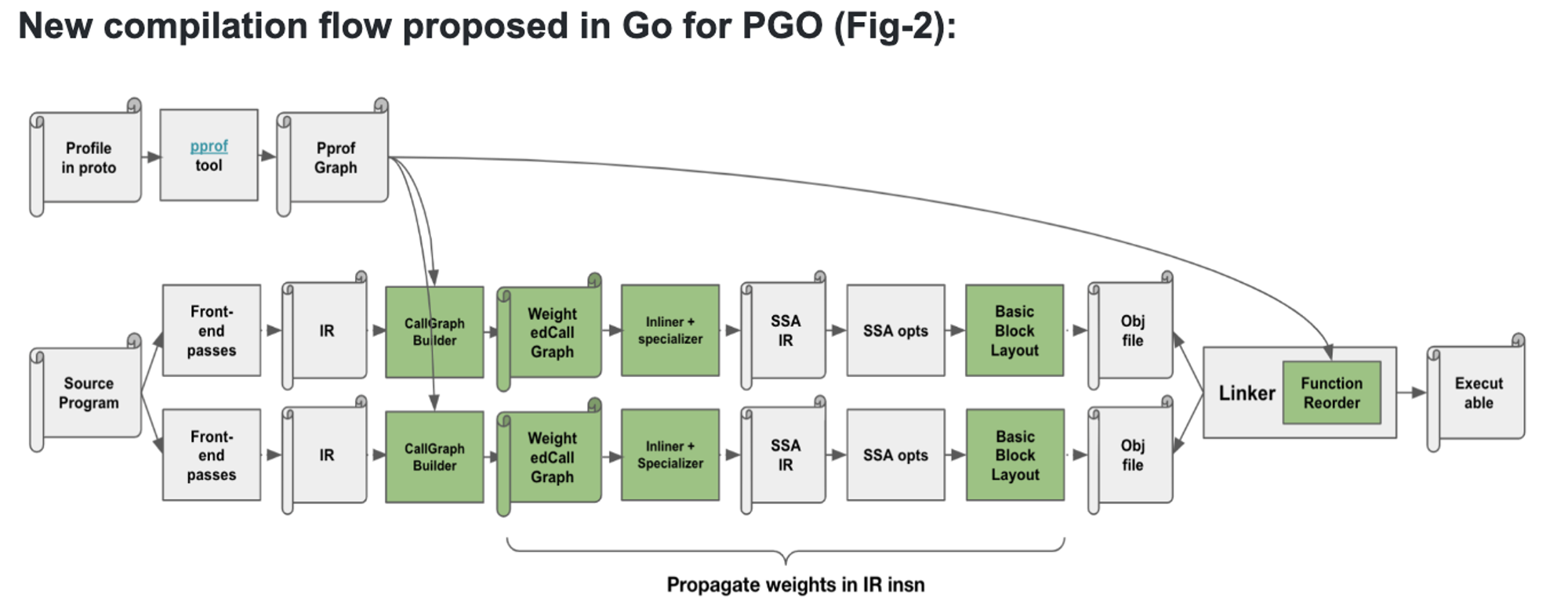
- CallGraphBuilder, WeightedCallGraph
- pprof 및 perf를 통해 생성된 profile을 상호작용할 수 있는 graph로 생성합니다.
- 모든 함수의 IR에 엣지와 노드 가중치를 갖는 호출 그래프를 만듭니다. 엣지와 노드 가중치는 pprof-graph에서 얻을 수 있습니다.
- CallGraphBuilder
- IR을 분석해서 패키지내의 함수 호출 관계를 만드는 역할을 함.
- WeightedCallGraph
- 생성된 CallGraphBuilder에 가중치를 추가한 버전.
- pprof 및 perf를 통해 생성된 profile을 상호작용할 수 있는 graph로 생성합니다.
- Profile Guide Inlining
- 이전에는 maxInlineBudget(80)이라는 고정된 값을 넘게되면 inline 하지 않음.
- profile로 분석했을 때 Hot Code 웨이트가 높다면 80을 넘어서게 되도 inline 할 수 있게 해줌.
- Hot Code만 inline되게 하고 다른 것은 inline 안되게 막아서 전체적인 양을 조절함.
- Hot Code의 기준은 전체 실행시간의 2% ⬆인 코드
- e.g)
go build -gcflags='-l=4' // golang ilining 수준 조절 옵션
gcc -finline-limit=160 your_program.c //gcc에서 사용할 때 inline 기준을 조절할 수 있음.
- Basic-block 재배치
- 컴파일 과정에서 가장 큰 이득을 줄 수 있는 연쇄 코드블록을 재배치함.
- 캐시 재사용 측면에서 가장 큰 이익을 가져다주는 방향으로 재배치함.
- EXT-TSP heuristic를 이용해서 최적화를 진행함.
- 두 연쇄를 세개의 가상의 연쇄로 만듬.
- 세개의 연쇄를 여러가지로 조합해서 가장 큰 성능을 제공하는 조합으로 선택함.
- 함수 재배치
- 링커에서 오브젝트 파일들을 병합하는 과정에서 여러 함수들이 섞이게 되고 이 과정에서 함수 재배치를 통해서 최적화를 진행함.
- 텍스트 섹션에서 함수를 가능한 자주 호출하는 함수에 가깝게 배치해서 캐시효율을 극대화합니다.
- 테스트 섹션: 실행되는 기계어 명령어들이 저장되는 부분을 말합니다.
- 가장 빈번하게 실행되는 함수부터 가장 적게 실행되는 함수까지 순서대로 우선순위를 매기는 방식으로 작동합니다.
- C3 휴리스틱 알고리즘.
- malloc, assistGC와 같이 직접 호출되는 케이스는 ordering에 포함되어야 함.
- 다른 GC 함수들(backgroundGC)은 독립적으로 실행되는 케이스의 경우에는 따로 oredering을 구성해서 재배치를 진행해야함.
- Code 전문화
- 함수를 간접적으로 호출할 때 함수포인터나 가상 메소드를 통해 호출하는 경우 추가적인 처리가 필요해서 성능저하 발생할 수 있음.(런타임에서 확인함.)
- hot 코드 호출하는 부분을 if-else 구조로 변환합니다.
- 이 경우 간접호출에 대한 오버헤드가 줄어들게 됨.
- 예시
package main
import "fmt"
type Animal interface {
Speak()
}
type Dog struct {}
func (d Dog) Speak() {
fmt.Println("Bark!")
}
type Cat struct {}
func (c Cat) Speak() {
fmt.Println("Meow!")
}
// before
func makeAnimalSpeak(animal Animal) {
animal.Speak()
}
// after
func makeAnimalSpeak(animal Animal) {
if dog, ok := animal.(Dog); ok {
dog.Speak() // 직접 호출로 변환
} else {
animal.Speak() // 기존의 간접 호출 유지
}
}
func main() {
var myAnimal Animal
myAnimal = Dog{} // Dog 인스턴스 생성
makeAnimalSpeak(myAnimal)
}
Golang에서 사용하기
테스트 해볼 Application
event worker
- sqs로 이벤트 데이터를 받은 후 유저의 데이터가 db(dynamodb)에 있는 유저인지 확인하고 버리거나 produce(키네시스, sqs)함
- EKS c5.xlarge 노드 위에 pod로 띄워져있음.
Throughput
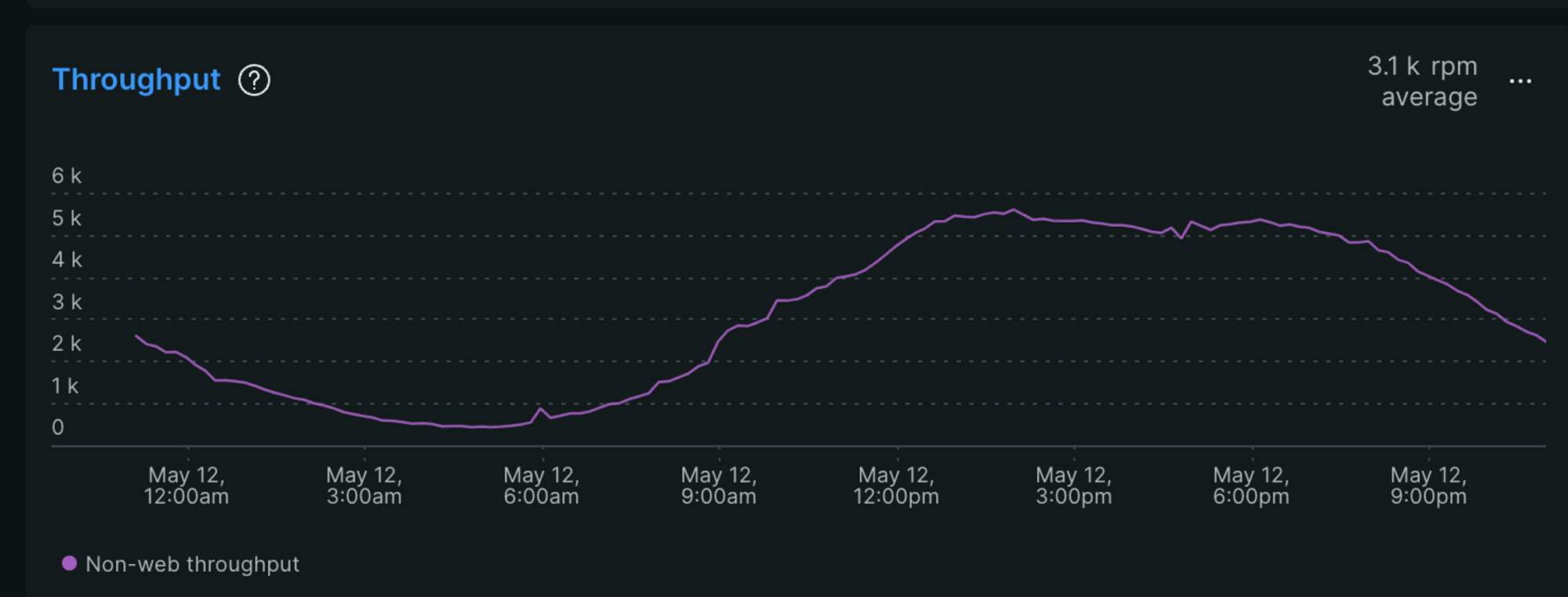
CPU 사용량
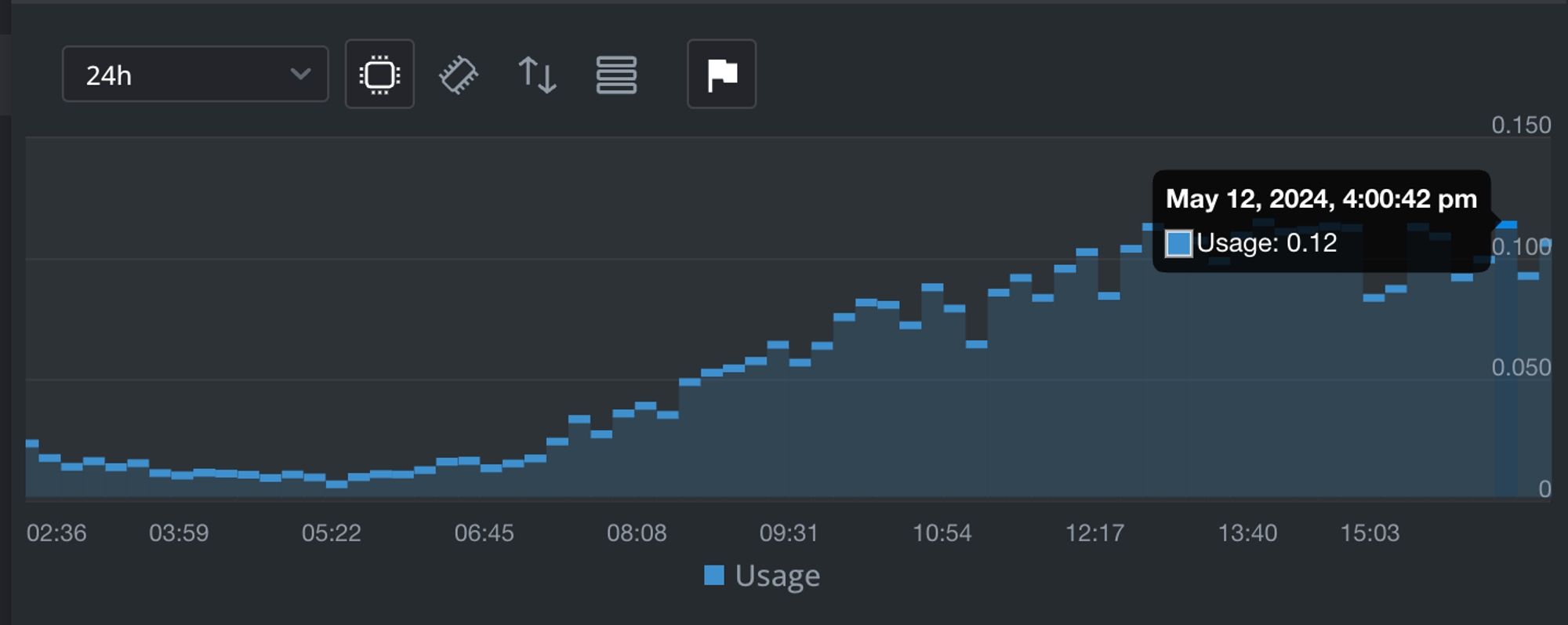
램 사용량
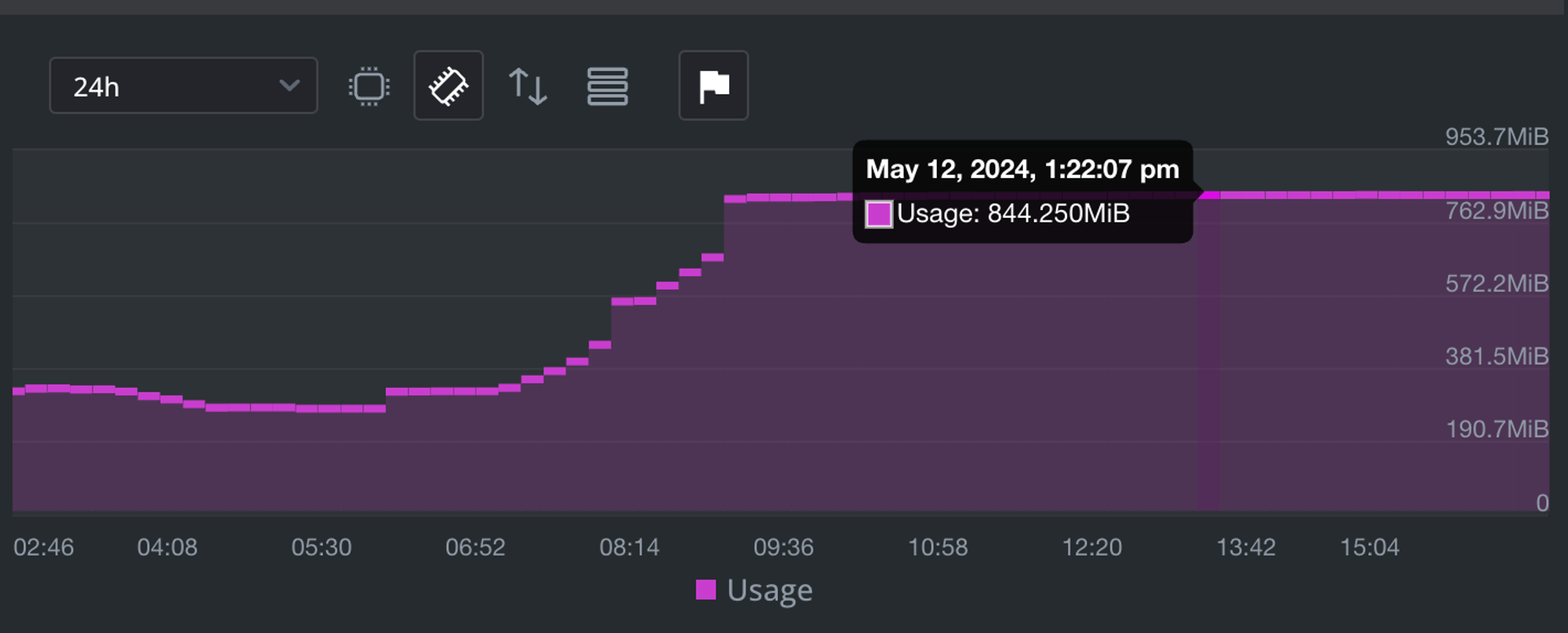
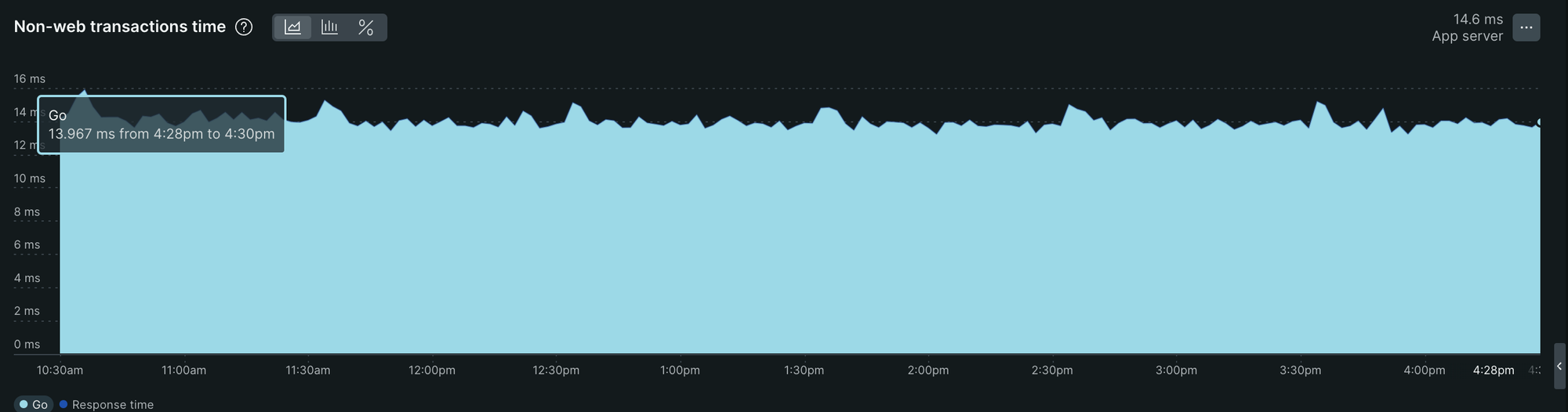
Transaction Time
15ms ~ 14ms 소요됨.

프로파일링하기
golang 1.22로 업그레이드 했습니다.
PGO하기 위해서 1.21 위로 업그레이드가 필요함
code 설정
package main
import (
// 생략
"net/http"
_ "net/http/pprof"
// 생략
)
func main(){
// 생략
go func() {
http.ListenAndServe("0.0.0.0:8080", nil) // port는 자유
// eks service에 8080 port 열려 있어서 사용함.
}()
// 생략
}
ClusterIP 상태의 pod라서 웹에서 접근하기 위해서 K8s Port forwarding을 사용했습니다.
/debug/pprof path로 접근하면 pprof 정보 확인할 수 있음.
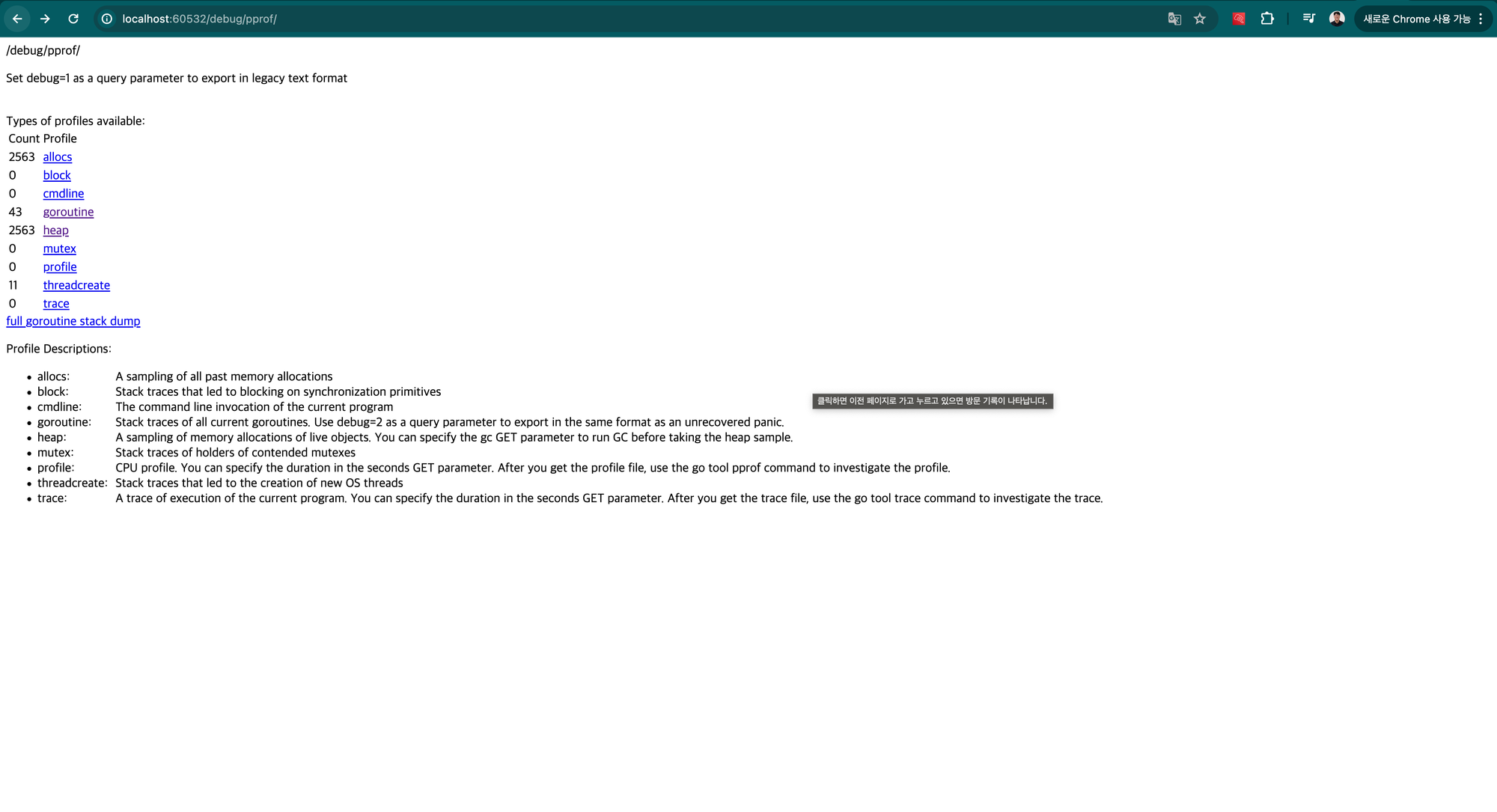
Profiling 다운로드 받기 30분동안 Profiling한 결과를 다운받았습니다.
curl http://localhost:60532/debug/pprof/profile\?seconds\=1800 --output profile.out
Dockerfile에서 go build 해줄 때 -pgo 옵션 추가함.
@go build -pgo=profile.out -o build/$(TARGET) -ldflags="$(LDFLAGS)" ./cmd/
// default.pgo
// 자동으로 default.pgo라는 파일을 찾아서 사용함.
go build
// use specific pgo
go build -pgo=path
비교 전/후
메모리
위에서 확인했던 것과 10MB정도 감소하긴 했지만 유의미하게 감소한 추세는 아님.
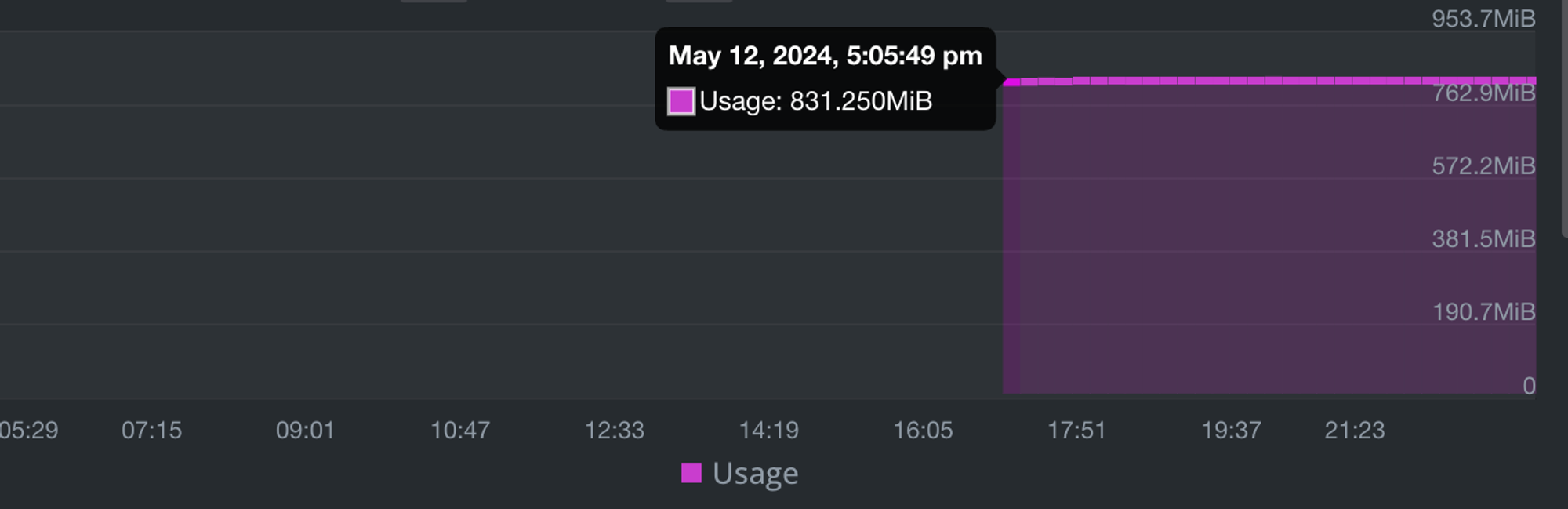
cpu
큰 변화가 느껴지지 않음.
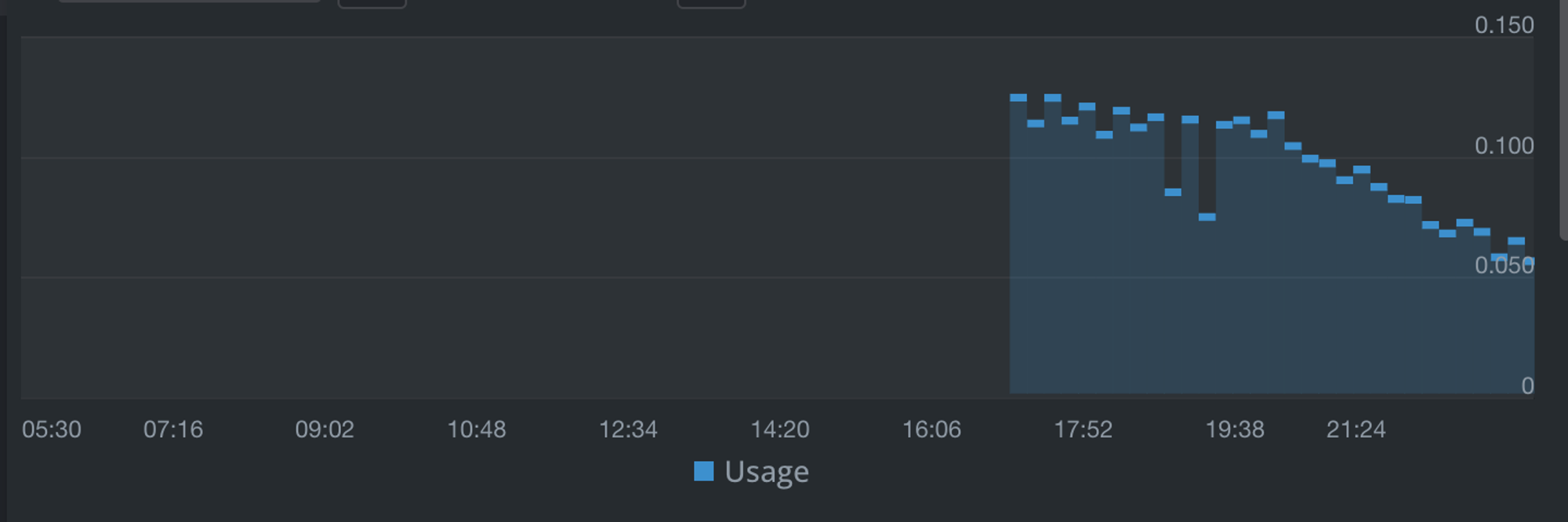
Transaction Time
12ms ~ 11ms 사이로 측정되며 기존 14ms 유의미하게 Transaction Time 약 10% 감소
FAQ
- Q1: Go 표준 라이브러리 패키지를 PGO로 최적화할 수 있나요?
- A: 가능함. GO에서 PGO는 전체 프로그램에 적용됩니다. 모든 패키지가 프로파일 가이드 최적화의 가능성을 고려하여 다시 빌드됩니다.
- Q2: 의존 모듈 내의 패키지를 PGO로 최적화할 수 있나요?
- A: 가능함. GO에서 PGO는 전체 프로그램에 적용됩니다. 의존성을 포함한 모든 패키지가 프로파일 가이드 최적화의 가능성을 고려하여 다시 빌드됩니다.
- Q3: 다른 GOOS/GOARCH 빌드에 동일한 프로파일을 사용할 수 있나요?
- A: 가능함. 프로파일의 형식은 OS와 아키텍처 구성을 통틀어 동일하므로, 다른 구성에서도 사용할 수 있습니다.
- Q4: PGO가 빌드 시간에 어떤 영향을 미치나요?
- A: PGO 빌드를 활성화하면 패키지 빌드 시간이 증가할 가능성이 있습니다. PGO 프로파일이 바이너리의 모든 패키지에 적용됨, 프로파일의 첫 사용은 의존성 그래프의 모든 패키지를 다시 빌드해야 함을 의미합니다.
- Q5. PGO가 바이너리 크기에 어떤 영향을 미치나요?
- A: PGO는 추가 함수 인라이닝으로 인해 약간 더 큰 바이너리를 생성할 수 있습니다.
- Q6. 단일 바이너리에 여러 시나리오가 발생할 수 있는 케이스면 어떻게 해야할지?
- A: 가장 큰 Hotpath를 이루는 루트의 방법을 사용하던가 혹은 각 케이스에 대해서 Profiling 한 결과를 Merge해서 사용하길 추천합니다.
결론
해볼 수 있는 최적화를 다 해봤을 때 추가로 사용해서 최적화를 더 해볼 수 있을 것 같음.
유의할 점
- Profiling을 한 데이터가 매우 중요하다. 대표적인 입력과 시나리오를 적용하는 것이 중요하다.
- application 및 환경에 따라 다르겠지만 직접 테스트 했을 때 10분간 했을 때와 30분간 했을 때의 profiling 결과에 나오는 함수 결과가 다르게 보이기도 했다.
좋았던 점
- 다이나믹한 결과가 나오지는 않는다. go의 공식 문서에서는 2 - 14% 정도의 성능향상을 이루어 낸다고 설명함.
- 또 Auto FDO를 지원하기 때문에 자동으로 PGO를 적용하는 프로세스를 구성해볼 수 있음.
- 위 결과에서는 CPU 타임과 Ram 극소 감소나 감소하지 않은 케이스도 있었지만 테스트 도중에 감소한 케이스도 있었습니다.
불편한 점
- Profiling 한 결과를 자동화해서 작업하게 만들 수 있는 과정을 만드는 것은 꽤나 귀찮은 일일 수 있을 것 같음.
- Profiling한 데이터의 상태가 대표적이지 않거나 여러 개의 루트를 대표하지 못한다면 최적화 될 수 없을 수 있다. 따라서 자기가 테스트 데이터를 구성해야할 수 도 있어서 한계가 있을 수 있다.
- 각 profiling을 합치는 것도 방법일 수 있음.
- 코드의 변화가 크거나 리팩토링이 빡세게 진행될 시에 이전 프로파일링의 결과가 소용없을 수 있음 따라서 PGO 없이 배포 후 다음 배포는 처음부터 프로파일링을 다시 해야함.
참고자료
- https://go.dev/doc/pgo
- https://go.googlesource.com/proposal/+/master/design/55022-pgo-implementation.md
- https://d2.naver.com/helloworld/8404108
- https://easyperf.net/blog/2018/07/09/Improving-performance-by-better-code-locality
- https://dl.acm.org/doi/10.5555/3049832.3049858
- https://groups.google.com/g/golang-nuts/c/PiFa55aX7Ds
- https://ieeexplore.ieee.org/document/9050435
'golang' 카테고리의 다른 글
| GRPC란 무엇인가? (0) | 2021.06.07 |
|---|